Deok Filho
Senior Product Manager at CoreWeave, building infrastructure that powers the future of intelligence. Leading SUNK (Slurm on Kubernetes) and Sandboxes.
Born in Brazil, grew up in family business → Brooks School → Northwestern Engineering → Google Cloud → CoreWeave.

Projects & Publications
New CoreWeave SUNK Capabilities Help Teams Build Modern AI Research Clusters
SUNK Self-service GA delivers one-click managed Slurm-on-Kubernetes clusters; SUNK Anywhere extends the same operating model to GKE, EKS, and other Kubernetes deployments.
Automated User Provisioning for Slurm Clusters
Industry-first automation synchronizing enterprise identities into SUNK clusters using SCIM protocols.
Scaling Reinforcement Learning with torchforge on CoreWeave Cloud
Meta, Stanford, and CoreWeave partnership achieving post-training runs on 512 H100 GPUs with improved efficiency.
CoreWeave Training Benchmarks Whitepaper
Comprehensive analysis of AI training performance benchmarks and optimization strategies for large-scale GPU clusters.
W&B Inference powered by CoreWeave
Seamless CoreWeave integration enabling ML teams to discover and evaluate open-source models within W&B.
MLPerf Record with NVIDIA GB200 Blackwell Cluster
Largest-ever MLPerf submission with 2,496 NVIDIA Blackwell GPUs achieving 2x faster training at 91% scaling efficiency.
inControl - Accessible Gaming Controller
One-handed video game controller for patients with hemiplegia with provisional patent filed.
Talks, Presentations & Demos
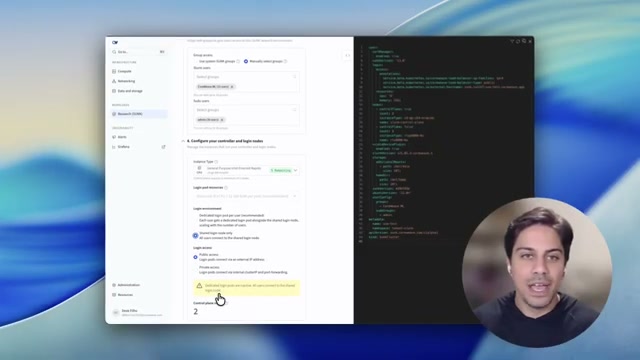
SUNK Self-service Demo
One-click production Slurm-on-Kubernetes clusters: nodes flow into Slurm, IAM SSH access, right-sized control plane, shared filesystem, and managed lifecycle. Also deployable as a Kubernetes CR for GitOps workflows.
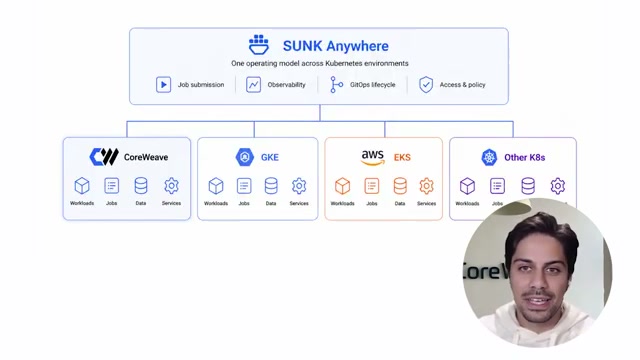
SUNK Anywhere Demo
Extends SUNK to GKE, EKS, and other Kubernetes deployments for one operating model across providers. Agent skills handle deployment with shared storage, GPU/Slurm metrics, and dashboards wired in.
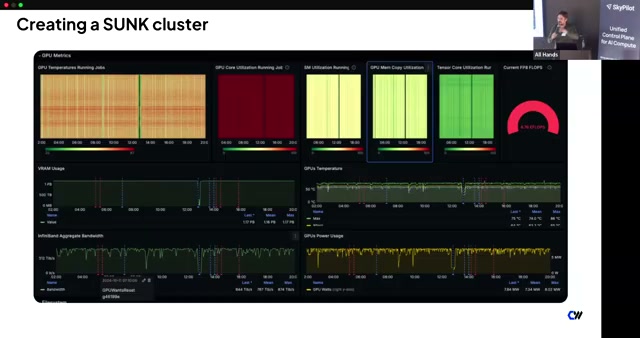
Training At Scale With Confidence: SkyPilot Integration with CoreWeave SUNK
SUNK overview plus the launch of running SkyPilot on SUNK: self-service clusters, ~70–80 hour MTBF on 1k-GPU jobs, automatic node replacement and job requeue, topology-aware scheduling, and GPU straggler detection via a NCCL plugin.
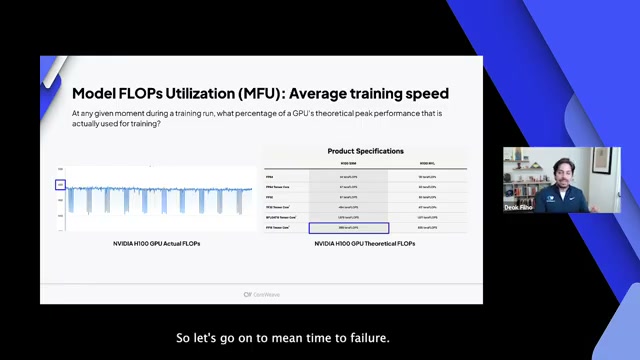
How to Measure and Optimize AI Infrastructure for Large-Scale Training
Discussion on achieving 20% more throughput and 97-98% utilization through optimization techniques.
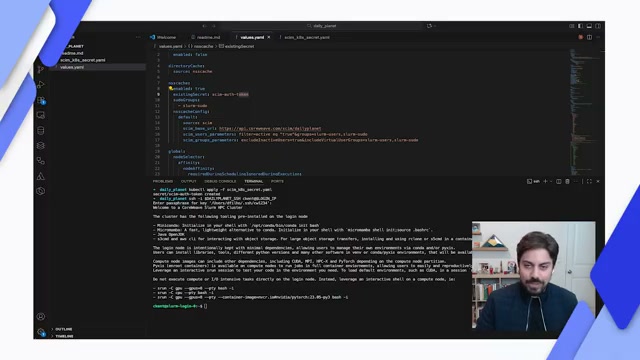
SUNK User Provisioning Demo
Demonstration of automated user provisioning for HPC workload management.

Networking Configurations on Google Cloud
Technical deep dive on networking configurations and best practices for cloud infrastructure.

Configuring Cloud Operations on Google Cloud
Comprehensive guide to setting up and managing cloud operations for production workloads.

API management with Apigee
In-depth exploration of API management patterns and implementation strategies using Apigee.


